"**By default, this handler serves static content from any of the \*/static, /public, /resources,\* and \*/META-INF/resources\* directories that are on the classpath**. "
// here our traverse stops at i == nums.length -2 // if as this case, i == curRange, it naturally // need one more step, and res would increase by 1 // else, it means that the curRangg has already covered // the nums.length - 1 for (inti=0; i < nums.length - 1; i++) { potential = Math.max(potential, i + nums[i]);
if (i == curRange) { res++; curRange = potential; } }
classSolution { publicintwiggleMaxLength(int[] nums) { // corner case, as described, if there are only 1 element return 1 // if there are two elements and they are not equal, return 2 if (nums.length == 1) { return1; }elseif (nums.length == 2) { if (nums[0] != nums[1]) { return2; } return1; }
// result is initialized as 1, as the rightest one is always regarded as a waggle intresult=1;
// intprevDiff=0; intcurDiff=0;
for (inti=0; i < nums.length - 1; i++) { curDiff = nums[i + 1] - nums[i]; if (prevDiff >= 0 && curDiff < 0 || prevDiff <=0 && curDiff > 0) { result++; // update prevDiff only when a waggle is found, and recordsits direction prevDiff = curDiff; } }
privatevoidbacktracking(int[] nums, int startIndex) {
// as the minimum valid sequence contains at least two elements, thus // add those path whose length is greater than 1 if (path.size() > 1) { set.add(newLinkedList<>(path)); }
for (inti= startIndex; i < nums.length; i++) {
/* * actually this kind of remove duplicate is non-sense * as it only function when the given array is like [4 6 7 7] * if it is changed to [4 7 6 7] it still causes duplicates */
// rule out duplicate elements in same level if (i > startIndex && nums[i] == nums[i - 1]){ continue; }
// we are not sure whether this time of calling would // add a element or not ,thus record the previous size intrecordPathSize= path.size();
// for the topest level elements, directly add it if (path.size() == 0) { path.add(nums[i]); }elseif (path.size() > 0) { // if current element is greater and equals to last added element if ( nums[i] >= path.get(path.size() - 1)){ path.add(nums[i]); } }
// recursively call this func backtracking(nums, i + 1);
// if we do add elements into the path, remove it if (path.size() > recordPathSize) { path.remove(path.size() - 1); } } } }
private List<List<Integer>> ans = newLinkedList<>(); private List<Integer> path = newLinkedList<>();
public List<List<Integer>> findSubsequences(int[] nums) {
backtracking(nums, 0); return ans;
}
privatevoidbacktracking(int[] nums, int startIndex) { // when traversing all the tree, add those path whose length is equal // and greater than 2 if (path.size() > 1) { ans.add(newLinkedList<>(path)); }
// number [-100, 100] maps to array ranged [0, 200] // records whether this num has been used int[] used = newint[201];
for (inti= startIndex; i < nums.length; i++) {
// if path is not empty and elment is less than last num or it has been used, skip if ( (!path.isEmpty() && nums[i] < path.get(path.size() - 1)) || used[nums[i] + 100] == 1 ) { continue; }
path.add(nums[i]); used[nums[i] + 100] = 1;
backtracking(nums, i + 1);
// avoid uncertain backtrack, ensure that whichever approach here must be successful add path.remove(path.size() - 1); } } }
public List<List<Integer>> permuteUnique(int[] nums) { Arrays.sort(nums); used = newboolean[nums.length]; backtracking(nums); return ans; }
privatevoidbacktracking(int[] nums) { // exits if (path.size() == nums.length) { ans.add(newLinkedList<>(path)); } for (inti=0; i < nums.length; i++) {
// here is pruning but in a branch level // as used[i - 1] = true means we are in the branch of nums[i -1] // which is less efficient than directly remove this whole branch
// if(used[i] || (i > 0 && used[i - 1] && nums[i] == nums[i - 1])) { // continue; // }; // here is the pruning in level level (the same level on the tree) if(used[i] || (i > 0 && !used[i - 1] && nums[i] == nums[i - 1])) { continue; };
private List<List<Integer>> ans = newLinkedList<>(); private List<Integer> path = newLinkedList<>();
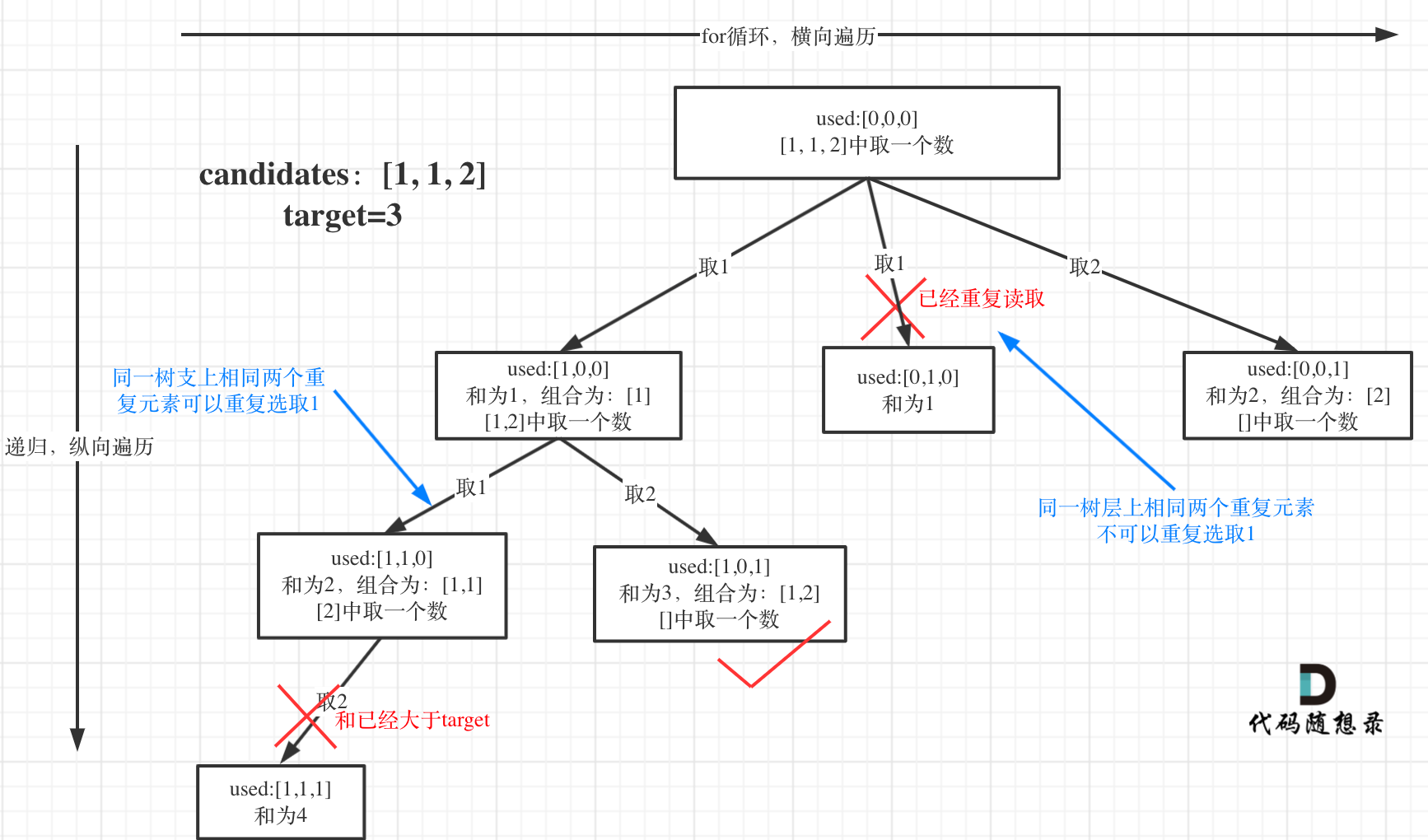
public List<List<Integer>> combinationSum(int[] candidates, int target) { backtracking(target, candidates, 0); return ans; }
privatevoidbacktracking(int target, int[] candidates, int startIndex) {
// if target is less than 0, exits if (target < 0) { return; // if find a successful combo, add it into ans }elseif (target == 0) { List<Integer> combo = newLinkedList<>(); combo.addAll(path); ans.add(combo); }
for (inti= startIndex; i < candidates.length; i++) { path.add(candidates[i]);
// note here, by seting the startIndex to i , it means that // the next element can still start with candidates[i] // this allows path like [2,2,3] // but at the mean time, it prevents the path like [3,2,2] // and through this way it removes some duplicates path backtracking(target - candidates[i], candidates, i); path.remove(path.size() - 1); } } }
private List<List<Integer>> ans = newLinkedList<>(); private List<Integer> path = newLinkedList<>();
public List<List<Integer>> combinationSum2(int[] candidates, int target) { Arrays.sort(candidates);
backtracking(candidates, target, 0);
return ans; }
privatevoidbacktracking(int[] candidates, int target, int index) {
if (target < 0) { return; // if find a successful combo, add it into ans }elseif (target == 0) { List<Integer> combo = newLinkedList<>(); combo.addAll(path); ans.add(combo); }
for (inti= index; i < candidates.length; i++) { // we need to avoid the duplicates in the same level for instance, // if we are chooseing the first num and the candidates is [1, 1, 1, 2] // then the second 1 would result in duplicates // this num is same as its left one && they are in the same level // then skip it if (i > index && candidates[i] == candidates[i - 1]){ continue; }
private List<List<String>> ans = newLinkedList<>(); private List<String> path = newLinkedList<>();
public List<List<String>> partition(String s) { backtracking(s, 0); return ans;
}
// for any String such as "aabbccd" // start with "a" then "aa", then "aab" privatevoidbacktracking(String s, int startIndex) {
// if we succeed to split the whole string, return if (startIndex >= s.length()) { List<String> combo = newLinkedList<>(); combo.addAll(path); ans.add(combo); return; }
for (inti= startIndex; i < s.length(); i++) { if (isPalindrome(s, startIndex, i)) { path.add(s.substring(startIndex, i + 1)); }else { continue; }
backtracking(s, i + 1); path.remove(path.size() - 1); }
}
// test if a sub string is palindrome from startIndex to the endIndex privatebooleanisPalindrome(String s, int startIndex, int endIndex) { inti= startIndex; intj= endIndex;
booleanans=true;
while ( i <= j) { if (s.charAt(i) == s.charAt(j)){ i++; j--; }else { ans = false; break; } }
classSolution { public List<List<Integer>> combinationSum3(int k, int n) { List<List<Integer>> res = newLinkedList<>(); List<Integer> path = newLinkedList<>(); backtracking(res, path, k, n, 1); return res; }
privatevoidbacktracking(List<List<Integer>> res, List<Integer> path, int k, int n, int index) {
// recursion exits if size == k && sum == n if (path.size() == k && getSum(path) == n) { List<Integer> combo = newLinkedList<>(); combo.addAll(path); res.add(combo); }
// traverse the [index, 9] for (inti= index; i < 10; i++) { // add this value into path path.add(i);
// traverse the right side numbers backtracking(res, path, k, n, i + 1);
// backtrack here path.remove(path.get(path.size() - 1)); }
}
// a helper method privateintgetSum( List<Integer> list) { intsum=0; for (Integer integer : list) { sum += integer; } return sum; } }
classSolution { public List<List<Integer>> combine(int n, int k) { List<List<Integer>> ans = newLinkedList<>(); List<Integer> path = newLinkedList<>(); myCombine(ans, path, n, k, 1); return ans; }
// for instance, n = 20, K = 3, // the tartet ans is the combination of every 2 elements in [1, 20] privatevoidmyCombine(List<List<Integer>> ans, List<Integer> path, int n, int k, int index) { // recursion exits if (path.size() == k) { List<Integer> combine = newLinkedList<>(); combine.addAll(path); ans.add(combine); return; } // this is to remove those unvalid recursion for (inti= index; i <= n - (k - path.size()) + 1 ; i++) { path.add(i); myCombine(ans, path, n, k, i + 1); path.remove(path.get(path.size() - 1));
classSolution { public TreeNode trimBST(TreeNode root, int low, int high) { if (root == null) { returnnull; } // as this is a BST, if root's val is larger than high // then all the right side nodes should be removed if (root.val > high) { return trimBST(root.left, low, high); } // the same with the left side if (root.val < low) { return trimBST(root.right, low, high); } // else, it means that root is within the target range // thus trim its child nodes root.left = trimBST(root.left, low, high); root.right = trimBST(root.right, low, high); return root;
classSolution { public TreeNode sortedArrayToBST(int[] nums) { // as I do not wanna change the array itself thus I choose to use to helper // function and express the range return buildBST(nums, 0, nums.length); }
// build the tree and return the root node in range [startIndex, endIndex) private TreeNode buildBST(int[] nums, int startIndex, int endIndex){ if (startIndex >= endIndex) { returnnull; }
privatevoidmyConvertTree(TreeNode root) { if (root == null) { return; }
// reflect the target tree, we can find that it starts counting // with the right node, then root node // and then the left node, thus we can traverse the tree in a variant in-order // i.e. right mid left myConvertTree(root.right);
// use a temp variable to record the updated value of the prev node thus we can // change all the nodes in one traverse if (temp != Integer.MIN_VALUE) { root.val += temp; }